그래프란?

- 그래프(Graph) 는 노드(정점, Vertex)와 간선(Edge) 의 집합으로 이루어진 수학적 구조입니다.
- 노드들은 어떤 대상을 의미하고, 간선은 이들 노드 사이의 관계나 연결을 표현합니다.
그래프 필수 구성 요소
정의에서도 알 수 있듯이 그래프는 노드와 간선의 집합으로 이루어져 있습니다.
- 노드(정점, Vertex)
- 그래프에서 다루고자 하는 대상(개체)입니다.
- 간선(Edge)
- 두 노드를 연결하는 선(관계)입니다.
- 유향 그래프(Directed Graph) 에서는 간선이 방향성을 가집니다.
예: - 무향 그래프(Undirected Graph) 에서는 간선이 방향성을 갖지 않습니다.
예:
- 유향 그래프(Directed Graph) 에서는 간선이 방향성을 가집니다.
- 두 노드를 연결하는 선(관계)입니다.
예를 들어, “사람들 간의 친구 관계”를 표현한다면 각 사람은 노드 친구 관계는 간선이 될 수 있습니다.
그래프를 표현하는 방법
1. 인접 행렬(Adjacency Matrix)
1.1. 정의
- 그래프에 존재하는 모든 노드 쌍(u, v)에 대해, “간선이 존재하는지(또는 가중치가 얼마인지)”를 나타내는 2차원 배열(행렬) 로 표현하는 방식입니다.
- 개라면, n×n 크기의 행렬을 만들고, 각 행과 열을 특정 노드에 대응시킵니다.
1.2. 예시 구조

위 그림과 같이 노드가 0, 1, 2, 3인 유향 그래프라면, 다음과 같은 2차원 리스트(또는 NumPy 배열)를 사용할 수 있습니다.
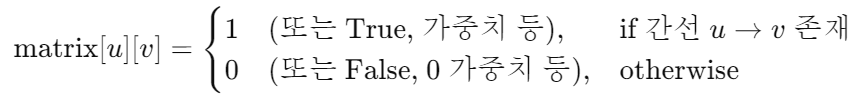

- “0 → 1”과 “0 → 2” 간선이 존재하므로 matrix[0][1] = 1, matrix[0][2] = 1
- “3 → 0” 간선이 존재하므로 matrix[3][0] = 1
- 그 외는 0(간선 없음)
- 만약 간선에 가중치가 존재했다면 가중치 값을 배열 값으로 갖는다.
“3 → 0” 간선이 존재하고 가중치가 6이면 matrix[3][0] = 6
- 만약 무향 그래프라면 행렬의 주대각선을 기준으로 대칭이다.
1.3. 특징
- 빠른 연결 여부 확인
- 특정 노드 u에서 v로 가는 간선이 있는지 O(1) 에 확인 가능
- 예: if matrix[u][v] == 1 ...
- 노드가 많은 그래프에선 메모리 사용이 클 수 있음
- 노드가 n개라면, 행렬의 크기는 n^2
- 간선이 별로 없는 “희소 그래프(Sparse Graph)”에서도 n^2 공간을 모두 사용해야 함.
- 밀집 그래프(Dense Graph) 에서 유리
- 간선이 매우 많아(대부분의 노드쌍이 연결), 메모리 낭비가 크지 않고, 빠른 조회가 가능함
2. 인접 리스트(Adjacency List)
2.1. 정의
- 각 노드에 대해, 해당 노드와 직접 연결된(인접한) 노드들의 목록을 저장하는 방식입니다.
- Python에서는 보통 딕셔너리 또는 리스트를 이용해 adj_list[u] 에 u와 연결된 이웃 노드들의 리스트(또는 집합)를 보관합니다.
2.2. 예시 구조
- 노드이 A, B, C, D인 그래프에서, 간선이 다음과 같다고 합시다(유향 그래프 예시)

- 인접 리스트는 다음과 비슷한 형태가 됩니다

2.3. 특징
- 희소 그래프(Sparse Graph)에 유리
- 실제 간선이 별로 없을 때, 필요한 연결 정보만 저장하므로 메모리 낭비가 적음.
- 특정 간선(u→v)의 존재 확인 시 O(k)
- adj_list[u]에 들어 있는 연결 목록을 확인해야 하므로, 최악의 경우 u의 인접 노드 개수(k)만큼 순회 필요.
- 특정 노드에 인접한 이웃 노드를 나열하기 쉬움
- adj_list[u]를 바로 열람하면 되므로 빠르고 직관적.
3. 간선 리스트(Edge List)
3.1 정의
- “간선이 몇 개 있다면, 그 모든 간선을 하나씩 기록한 목록”이 곧 간선 리스트 입니다.
- 그래프의 노드들을 별도로 관리(예: 집합, 리스트)하고, 간선(Edge) 들을 “(출발 노드, 도착 노드)” 형태로 모두 나열하여 리스트에 담아 놓습니다.
3.2 예시 구조 (유향 그래프)
예를 들어, 유향 그래프(Directed Graph)에서 노드이 A, B, C, D이고,
간선이 아래와 같다고 해봅시다.
- A → B
- A → C
- B → D
- C → D
- D → A
이를 간선 리스트로 표현하면, (출발, 도착) 튜플을 원소로 하는 리스트가 됩니다.
edges = [
("A", "B"),
("A", "C"),
("B", "D"),
("C", "D"),
("D", "A")
]3.3. 예시 구조 (무향 그래프)
무향 그래프(Undirected Graph)에서 노드이 A, B, C, D이고,
간선이 아래와 같다고 해봅시다.
- A - B
- A - C
- B - D
- C - D
이를 간선 리스트로 표현하면, (노드1, 노드2) 튜플을 원소로 하는 리스트를 만들 수 있습니다.
무향이므로 (A, B)는 (B, A)와 같은 간선을 의미하니, 중복 기록에 주의해야 합니다.
“(더 작은 노드, 더 큰 노드) 형태로만 저장한다”는 규칙을 정해서 중복을 방지할 수도 있습니다.
edges = [
("A", "B"),
("A", "C"),
("B", "D"),
("C", "D")
]
3.4 특징
- 구조가 단순하고 직관적
- 그래프의 연결 관계를 “간선 단위”로 파악하기 쉽습니다.
- 예: MST(최소 신장 트리)를 찾는 Kruskal 알고리즘 같은 경우, 모든 간선을 정렬해서 처리하므로 간선 리스트가 바로 유용합니다.
- 인접 정보 확인(Adjacency)에는 비효율적
- 어떤 노드 u에서 v로 가는 간선이 있는지 확인하려면, 전체 간선 리스트를 뒤져야 합니다(최악 O(e), e = 간선 수).
- 인접 리스트(Adjacency List)나 인접 행렬(Adjacency Matrix)에 비해 u의 이웃 노드를 빠르게 찾기는 어렵습니다.
- 희소/밀집 그래프에 모두 사용 가능하지만
- 간선 수 e가 적어도, 혹은 많아도 단순히 리스트 크기가 달라질 뿐이므로 구조적으로 문제는 없습니다.
- 다만, 인접 리스트나 인접 행렬에 비해 장점이 큰 경우는 “간선을 직접 순회해야 하는 알고리즘”을 사용할 때입니다.
- 메모리 사용량
- 오직 간선 수 e에 비례합니다(간선을 (u,v) 튜플로 기록).
- “노드 수가 매우 많지만 간선이 극도로 적은” 그래프에서도, 불필요한 공간 낭비가 없이 필요한 간선만 저장할 수 있습니다.
요약
| 구분 | 인접 행렬 (Adj. Matrix) | 인접 리스트 (Adj. List) | 간선 리스트 (Edge List) |
| 구조 | 크기의 2차원 배열 | 각 노드에 대해 인접한 노드 목록(리스트·딕셔너리 등) | 간선 자체를 “(u, v)” 튜플 목록으로 모두 나열 |
| 간선 존재 조회 | O(1) (배열 인덱스 접근) | O(k) (k는 노드 u의 인접 노드 수) | O(e) (전체 간선 수 e를 순회할 수도 있음) |
| 메모리 사용량 | O(n^2) | O(n + e) ( 노드 n, 간선 e) | O(e) (간선 개수) |
| 희소 그래프에 대한 효율성 | 간선이 적어도 n^2 공간을 사용하므로 비효율적 | 필요한 연결 정보만 저장하므로 효율적 | 필요한 간선만 목록에 기록하므로 메모리 낭비 적음 |
| 밀집 그래프에 대한 효율성 | 간선이 매우 많을 경우 공간 낭비가 크지 않고 조회가 빠름 | 간선이 너무 많으면 인접 리스트의 크기가 커지고 관리 비용 증가 | 간선이 매우 많아도 e가 커짐에 따라 리스트 길이도 증가, 조회 비용도 커짐 |
| 장점 | - 특정 간선(u→v) 존재 여부를 O(1)에 확인 - 빠른 조회 |
- 특정 노드에 인접한 이웃 리스트를 빠르게 가져옴 - 희소 그래프에 메모리 효율적 |
- 구조가 단순, 모든 간선을 직접 확인 가능 - Kruskal 등 “간선 중심” 알고리즘에서 유리 |
| 단점 | - 노드가 많고 간선이 적으면 대부분 0인 행렬로 메모리 낭비 | - u→v 간선 존재 여부 확인 시 O(k) 순회 필요 | - 특정 간선 존재 여부 또는 특정 노드의 인접 노드 조회는 최악 O(e)로 느림 |
'자료 구조( data structure)' 카테고리의 다른 글
| [자료 구조 / data structure] 배열(Array)에 대해 알아보자 (0) | 2024.09.15 |
|---|